In 2020, tired of every search engine seemingly having suboptimal results and missing the instant answers I wanted, I decided to make a search engine for myself.
I knew making a general-
A few weeks ago I decided to rewrite metasearch as (brace for it) metasearch2 (my project names only continue to get more original).
In this rewrite I implemented several of the things I wish I would’ve done when writing my first metasearch engine, including writing it in a blazingly fast 🚀🚀🚀 language.
There’s a hosted demo at s.
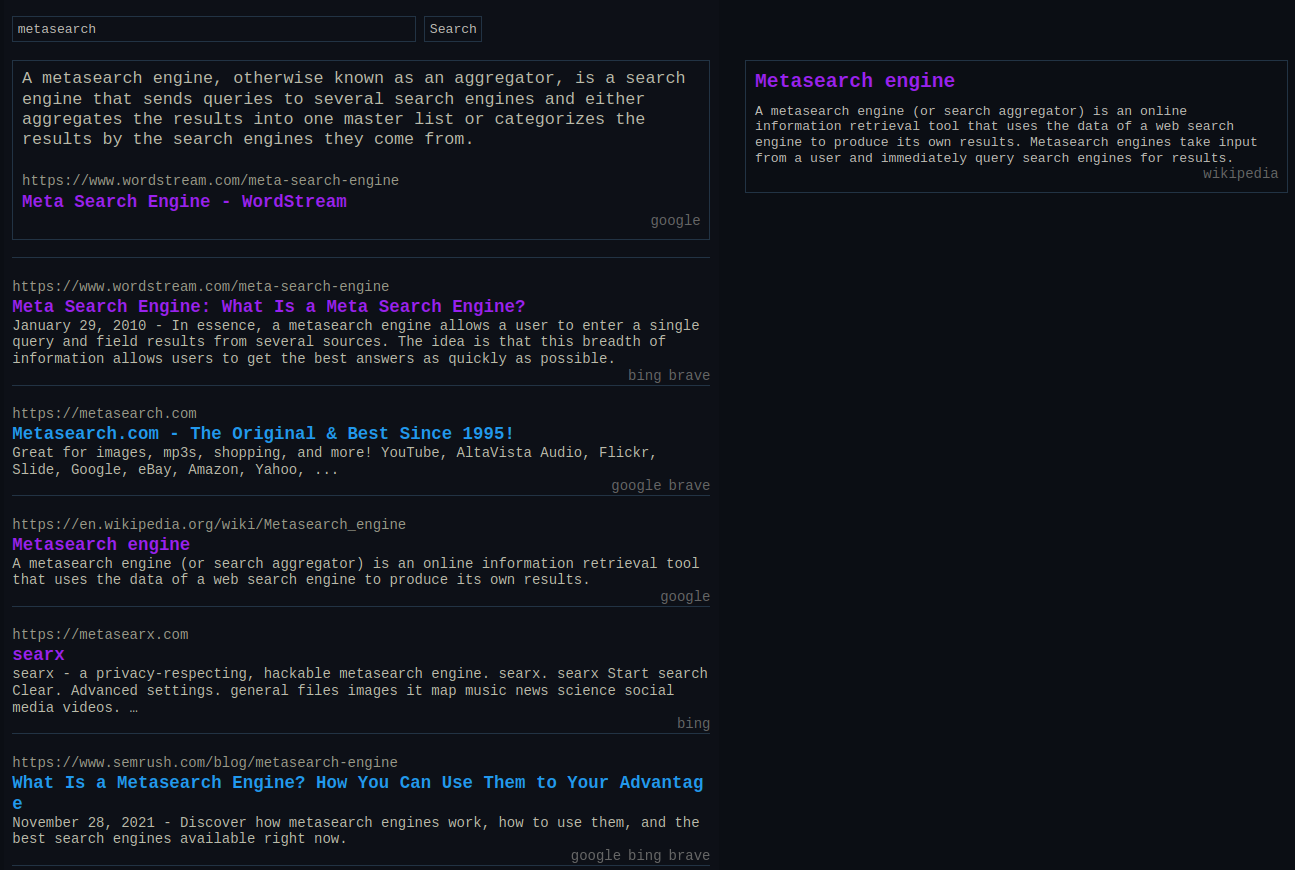
Other (meta)search engines
First, some prior art.
The metasearch engine most people know is probably Searx (now SearxNG), which is open source, written in Python, and supports a very large number of engines.
It was the biggest inspiration for my metasearch engine. The main things I took from it were how result engines are shown in the search page and its ranking algorithm.
However, as mentioned previously, it’s slow and not as hackable as their readme would like you to think.
The (probably) second most well-
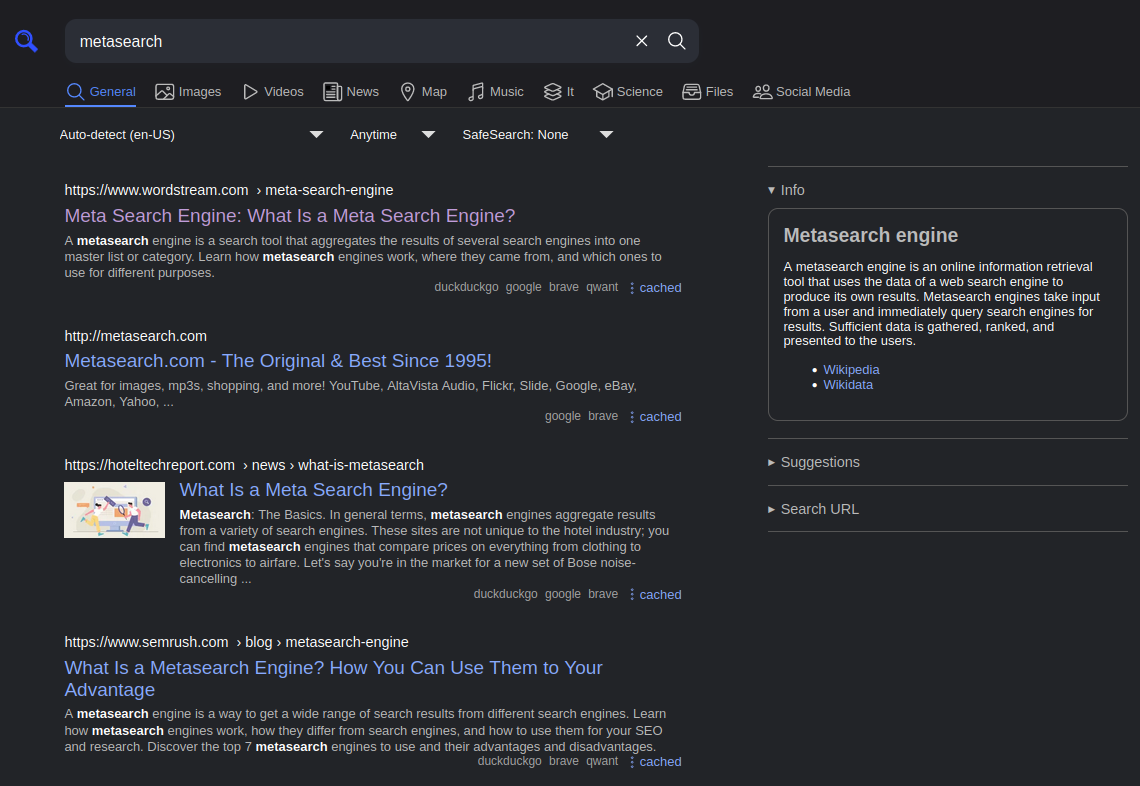
Also, of course, there’s my metasearch engine. Instead of just listing what engines I use, I’ll tell my opinion of every search engine that I think is interesting. I haven’t used some of these in years, so if you think their quality has changed in that time, let me know.
- Google: Some people deny it, but from my experience it still tends to have the best results out of any other normal search engine. However, they do make themselves somewhat annoying to scrape without using their (paid) API.
- Google’s API: It’s paid, and its results appear to be worse sometimes, for some reason. You can see its results by searching on Startpage (which sources exclusively from Google’s API). However, you won’t have to worry about getting captcha’d if you use this.
- Bing: Bing’s results are worse than Microsoft pretends, but it’s certainly a search engine that exists. It’s decent when combined with other search engines.
- DuckDuckGo/Yahoo/Ecosia/Swisscows/You.com: They just use Bing. Don’t use these for your metasearch engine.
- DuckDuckGo noscript: Definitely don’t use this. I don’t know why, but when you disable JavaScript on DuckDuckGo you get shown a different search experience with significantly worse results. If you know why this is, please let me know.
- Brave: I may not like their browser or CEO, but I do like Brave Search. They used to mix their own crawler results with Google, but not anymore. Its results are on-par with Google.
- Neeva: It doesn’t exist anymore, but I wanted to acknowledge it since I used it for my old metasearch engine. I liked its results, but I’m guessing they had issues becoming profitable and then they did weird NFT and AI stuff and died.
- Marginalia: It’s an open source search engine that focuses on discovering small sites. Because of this, it’s mostly only good at discovering new sites and not so much for actually getting good results. I do use it as a source for my metasearch engine because it’s fast enough and I think it’s cute, but I heavily downweigh its results since they’re almost never actually what you’re looking for.
- Yandex: I haven’t used Yandex much. Its results are probably decent? It captchas you too frequently though and it’s not very fast.
- Gigablast: Rest in peace. It’s open source, which is cool, but its results sucked. Also the privacy.sh thing they advertised looked sketchy to me.
- Mojeek: I’m glad that it exists, but its results aren’t very good. Also it appears to be down at the time of writing, hopefully it’s not going the way of Gigablast.
- Metaphor: I found this one very recently, its results are impressive but it’s slow and the way they advertise it makes me think it’ll stop existing within a couple years.
Scraping
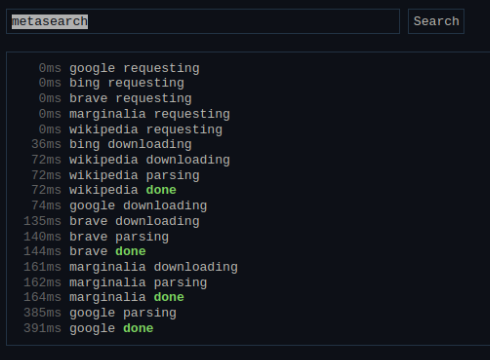
If you didn’t figure it out already, the engines I use for my metasearch engine are Google, Bing, Brave, and Marginalia. Some of these have APIs, but I chose not to use them due to pricing, worse results, and increased complexity due to requiring API keys. Scraping the sites is relatively easy. In my NodeJS implementation I used Cheerio for parsing the HTML, and in my Rust implementation I used Scraper. They’re both very nice. The most annoying part of scraping is just figuring out what selectors to use, but it’s not too bad. To provide an example, here’s the CSS selectors I use for Google:
- Search result container:
div.(Search results are usually ing > div, div. xpd > div:first- child .g, but not always. Other results, including ads, are in.xpd, but the:first-filters out the advertisements since ads never have a div as their first element)child - Title:
h3 - Link:
a[href](For some search engines you have to get the text instead of the href, and for Bing you have to get the href and then base64 decode a parameter since it’s a tracking URL. Google used to put a tracking URL on theiratags too, but it seems to have mostly been removed, except on the links for featured snippets). - Description:
div[data-(I don’t like this at all, but Google is inconsistent with how descriptions are done in their HTML so both selectors are necessary to reliably get it).sncf], div[style='-webkit- line- clamp:2']
Note how I avoid using class names that look randomly generated, only using g and xpd (whatever they stand for) since I’ve noticed those never change, while the other random class names do change every time Google updates their website.
You can check my source code and SearxNG’s if you need help figuring out what selectors to use, but you should always check your target site’s HTML in devtools.
Some websites make themselves annoying to scrape in ways that aren’t just making their HTML ugly, though. Google is the major culprit here. Google appears to always captcha requests coming from a Hetzner IPv6, Google will block your requests after a while if you’re using your HTTP client library’s default user agent, and Google captchas you if you make too many queries, especially ones with many operators. A couple other things you should watch out for that you might not notice are that you should make sure your TCP connections are kept alive by your HTTP client library (usually done by reusing the same Client variable), and making sure compression is enabled (which can sometimes save hundreds of milliseconds on certain search engines).
Ranking
The algorithm I use for ranking is nearly identical to the one Searx uses, and it’s surprisingly effective for how simple it is.
def result_score(result):
weight = 1.0
for result_engine in result['engines']:
if hasattr(engines[result_engine], 'weight'):
weight *= float(engines[result_engine].weight)
occurences = len(result['positions'])
return sum((occurences * weight) / position for position in result['positions'])Note that the position is 1-
Instant answers
Instant answers are the widgets that show up when you search things like math expressions or “what’s my ip”.
I think Google calls them just “answers”, but that can get confusing.
In my old metasearch, I had a lot of unique ones for things like pinging Minecraft servers and generating lorem ipsum text.
In my rewrite I didn’t implement as many since I don’t have as much of a need for them anymore, but I still did implement a few (and I haven’t finished adding all the ones I want yet).
My favorite engine I implemented in my rewrite is the calculator, which is powered by a very neat Rust crate I found called fend.
This makes it able to calculate big math expressions and do things like unit conversions.
I did have to add a check to make it avoid triggering on queries that probably weren’t meant to be calculated, though.
I also added some checks to support queries like ord('a') and chr(97) (I wasn’t able to add a custom function to fend to support chr, so it has a very big regex instead :3).
I imagine you already have ideas for instant answers you could add.
If you want more inspiration, a good source with over a thousand instant answers is DuckDuckHack (which DDG unfortunately killed).

Another thing I chose to do is to use Google’s featured snippets and display them similarly to instant answers.
Also, I made it so if a StackExchange, GitHub, or docs.
Rendering results
This part is mostly easy, since search engines usually don’t have any complex styling.
You can use whatever web/
Your turn
There’s several things I intentionally omitted for the sake of simplicity in my metasearch engine.
This includes pagination, the ability to search for images, reverse-